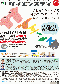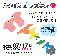

【機械学習基礎研究3】
倒立状態維持の強化学習(割引率による学習成果の違い)
前回に引き続き、倒立状態維持の強化学習を行います。前回、貪欲率は大きいほど(0.9あたり)が良さそうだったので、今回は貪欲率を0.9に固定したまま、割引率(未来に得られると期待される報酬をどの程度考慮するを表す率)を0から1.0まで0.1づつ変化させて学習成果の違いを確かめます。
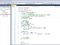
Q学習のパラメータ
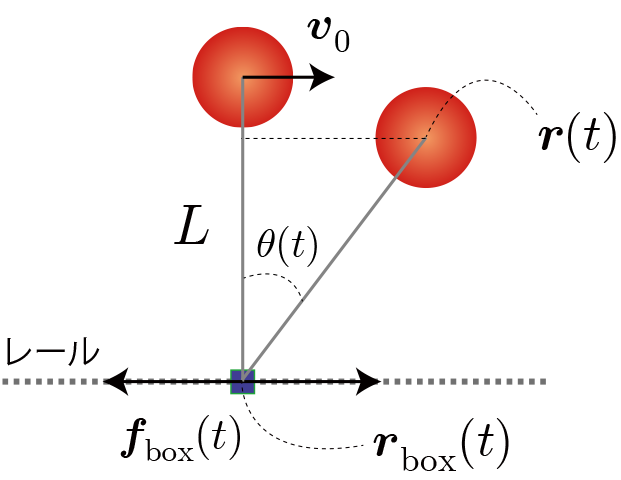
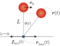
環境と行動と利得の定義(行動価値関数の定義)
前回は相対位置を10分割しましたが、少し改良して角度を10分割することにします。なお、力の分割数は前回と同様の20個です。前回と同様、環境:10、行動:20となり、最適行動価値関数は10×20の配列で表せます。あと、滑車が重いほどおもりの運動の影響が小さくなるので、問題設定の難易度を下げるために滑車の質量を10倍とします。
なお、利得はおもりの位置エネルギー($mgz$)とし、目標達成(5秒間落下しない)やペナルティー(5秒以内に落下)は今回も与えないことにします。
Q学習の表式とパラメータの値
\begin{align} Q^{(i+1)}(s,a) \leftarrow Q^{(i)}(s,a)+\eta\left[ r+\gamma \max\limits_{a'} Q^{(i)}(s',a') -Q^{(i)}(s,a) \right] \end{align}
$s$ : 時刻tにおける状態。$s(t)$と同値。
$a$ : 時刻tにおける行動。$a(t)$と同値。
$r$ : 時刻tの行動で得られた利得。$r(t+1)$と同値。
$Q(s, a)$ : 状態$s$における行動aに対する行動価値関数。上付き添字($i$)は学習回数を表す。
$\gamma$ : 割引率($0< \gamma \le 1$)
$\eta$ : 学習率($0< \eta \le 1$)
$s'=s(t+1)$
今回の設定
行動時間間隔:0.01(0.01秒ごとに行動を選択・実行する)
学習回数(episode):10000
学習率($\eta$):0.1(行動価値関数の更新時の変化率)
貪欲率($\epsilon$):0.9(行動価値関数で予測される利得の期待値が最大となる行動を選択する率)
今回は割引率(未来に得られると期待される報酬をどの程度考慮するを表す率($\gamma$)を0~1.0まで変化させて、その結果を比較します。
学習結果
割引率$\gamma$を0から1.0まで0.1ずつ変化させた際の、学習回数に対する成功率(100回学習ごとの平均)のグラフを示します。
$\gamma=0$
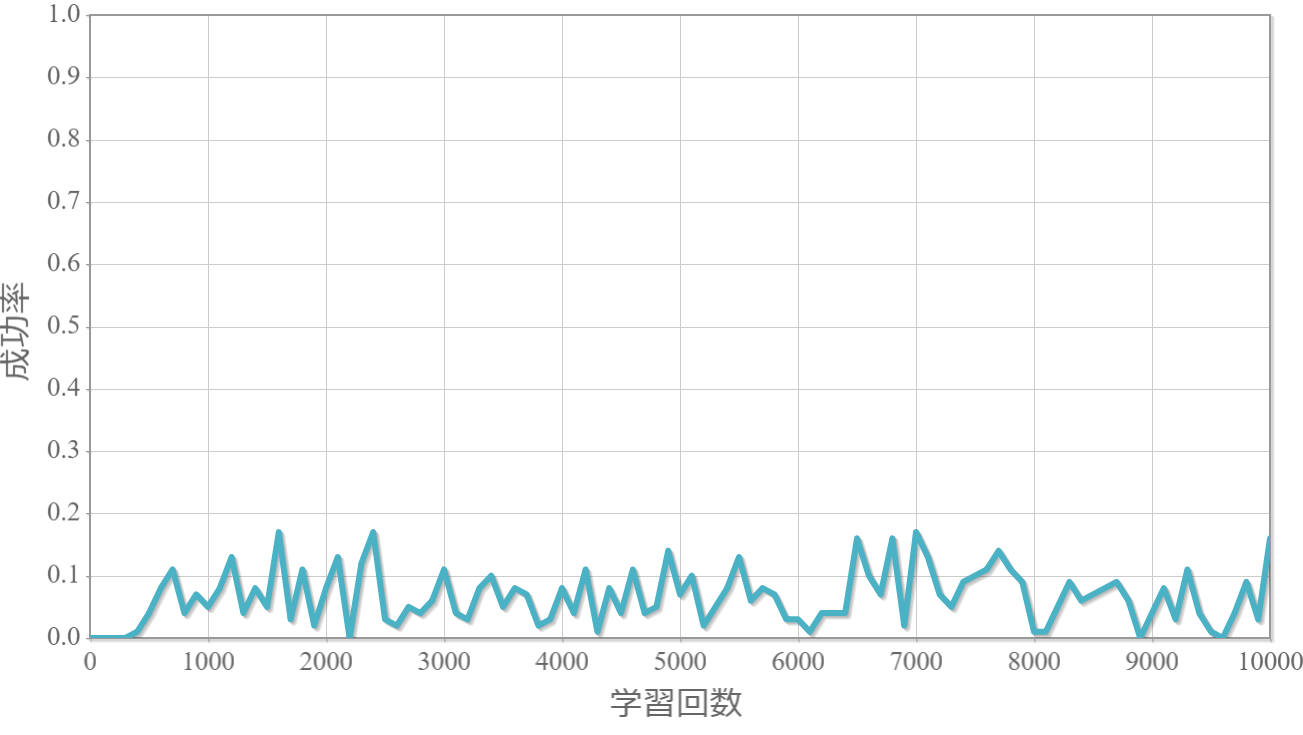
$\gamma=0.1$
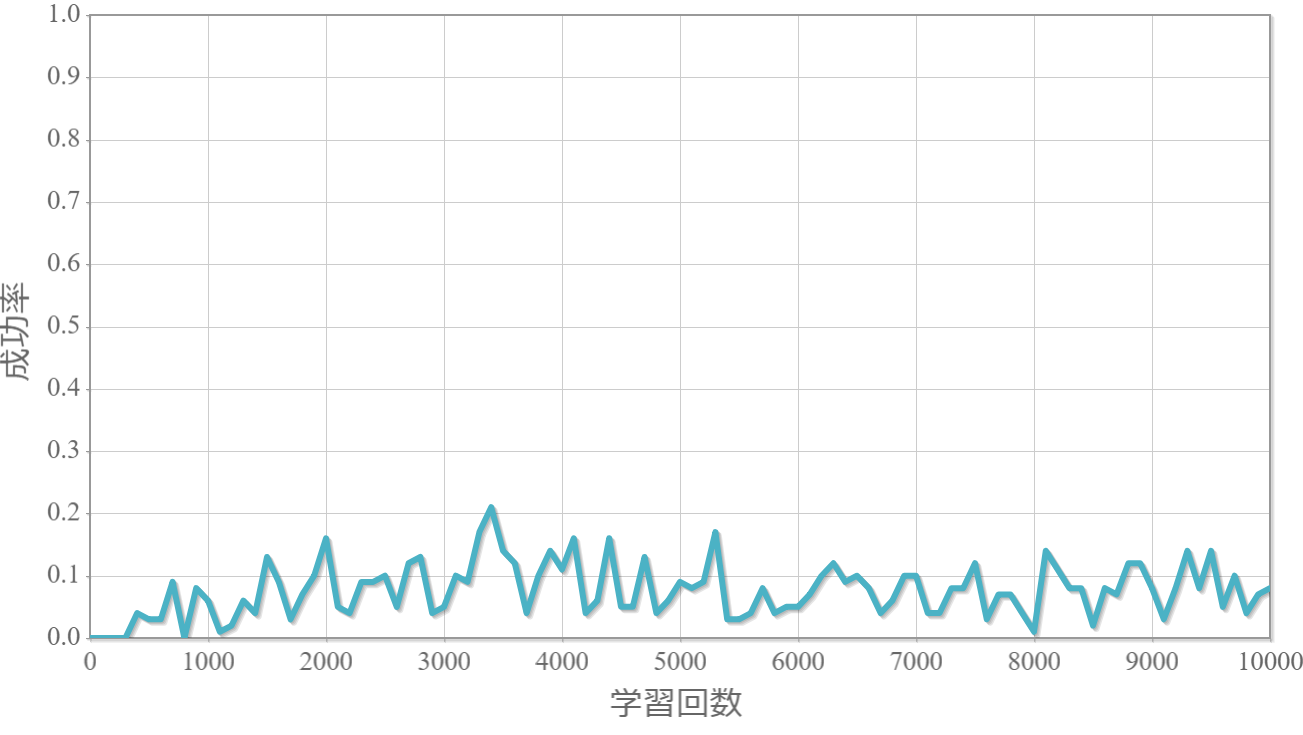
$\gamma=0.2$
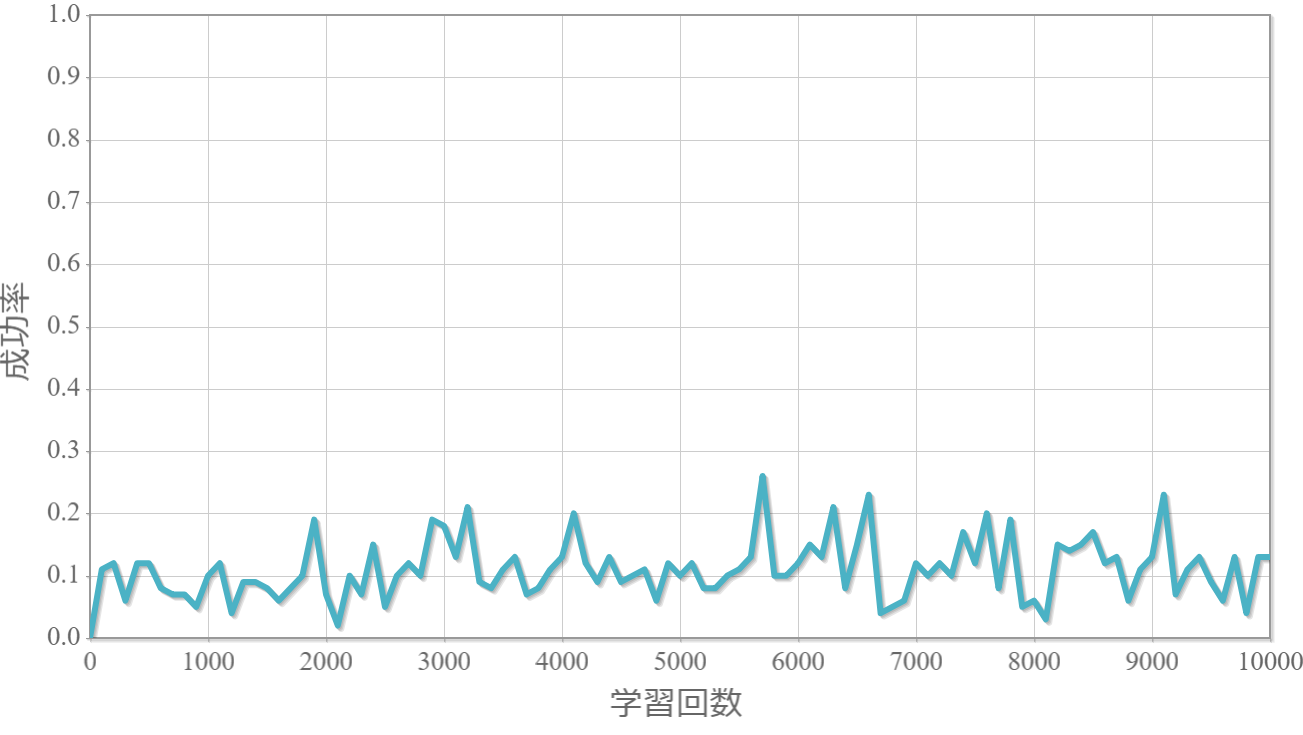
$\gamma=0.3$
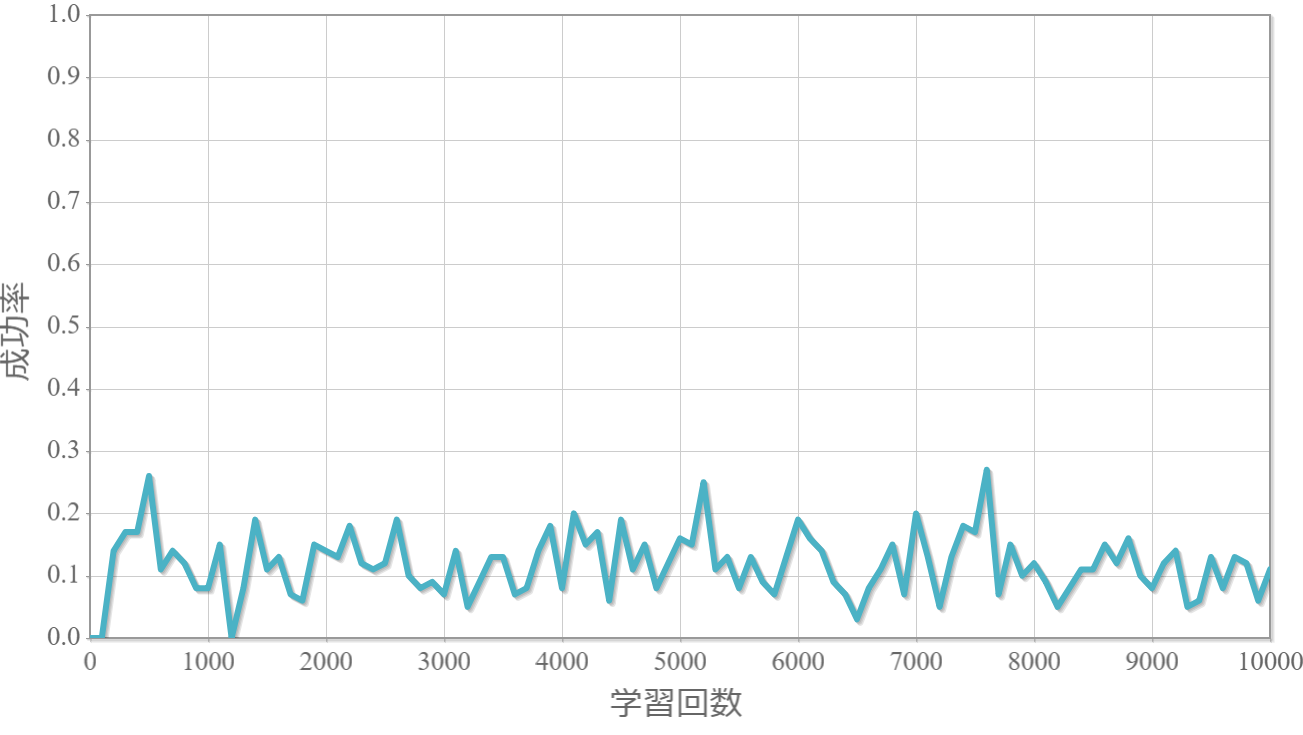
$\gamma=0.4$
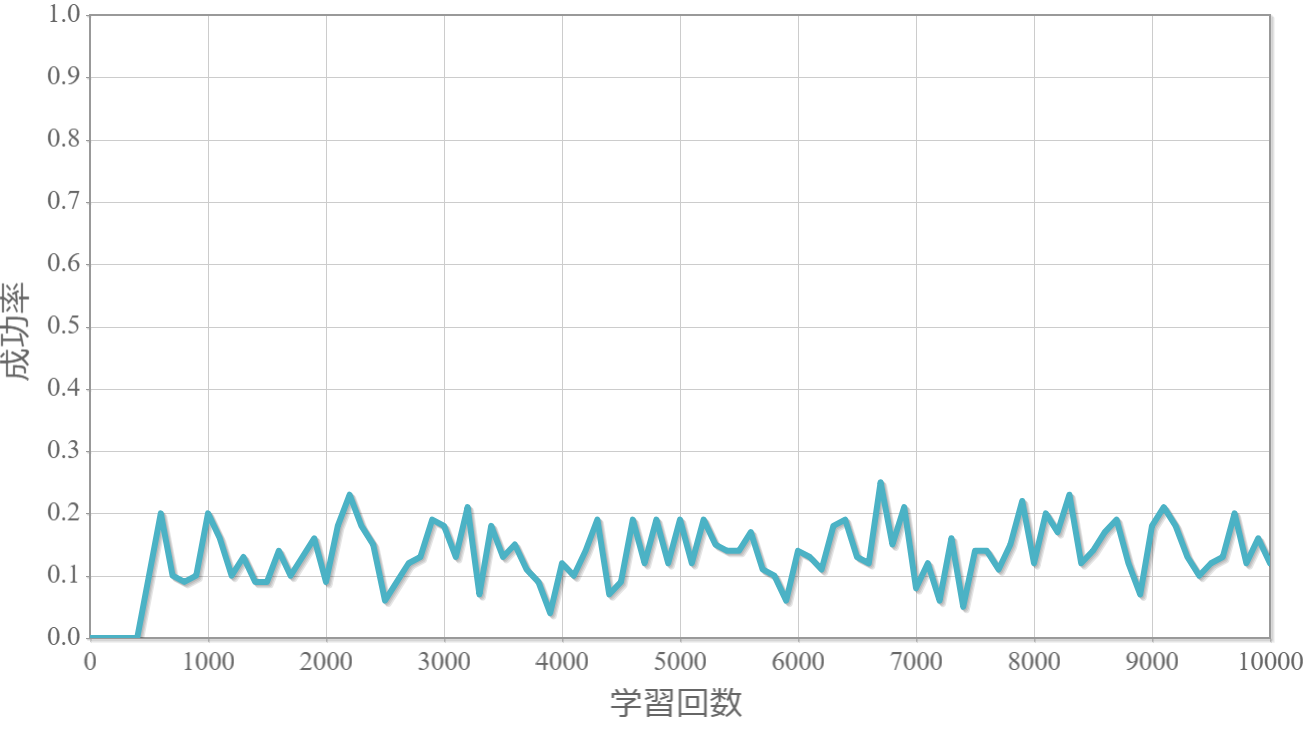
$\gamma=0.5$
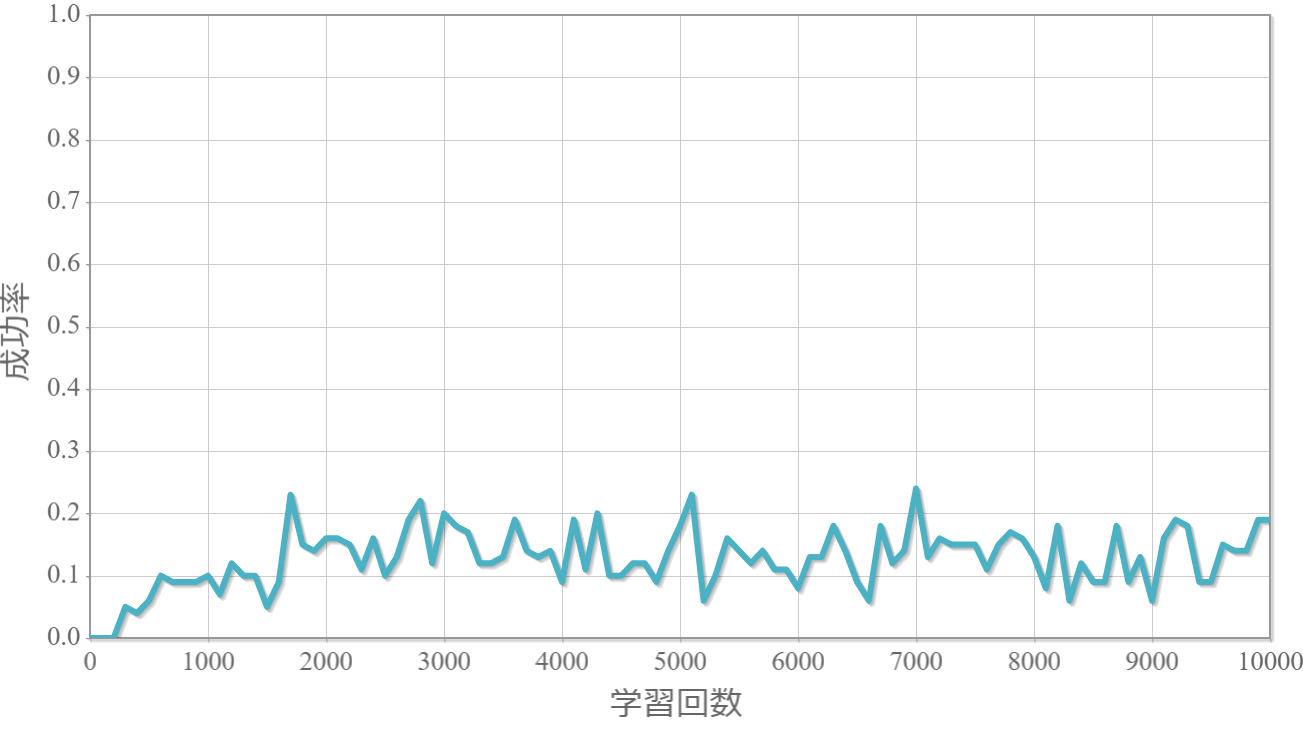
$\gamma=0.6$
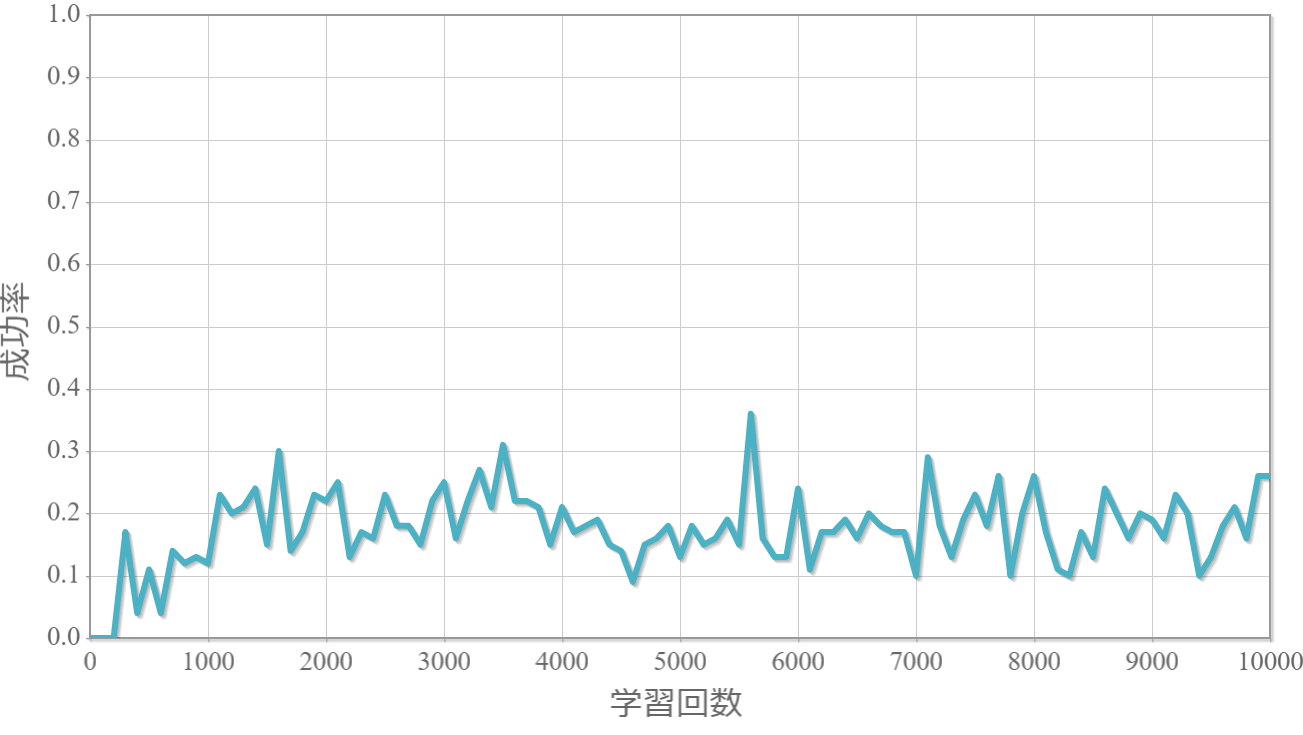
$\gamma=0.7$
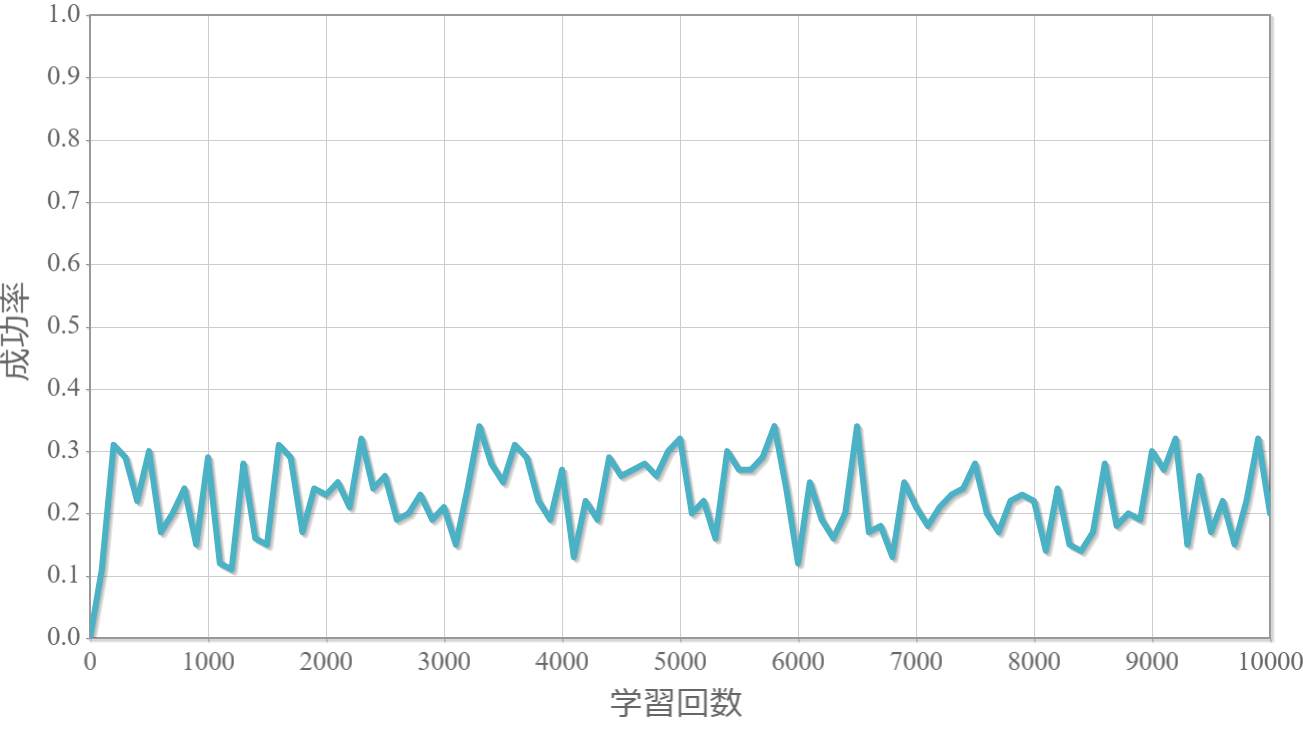
$\gamma=0.8$
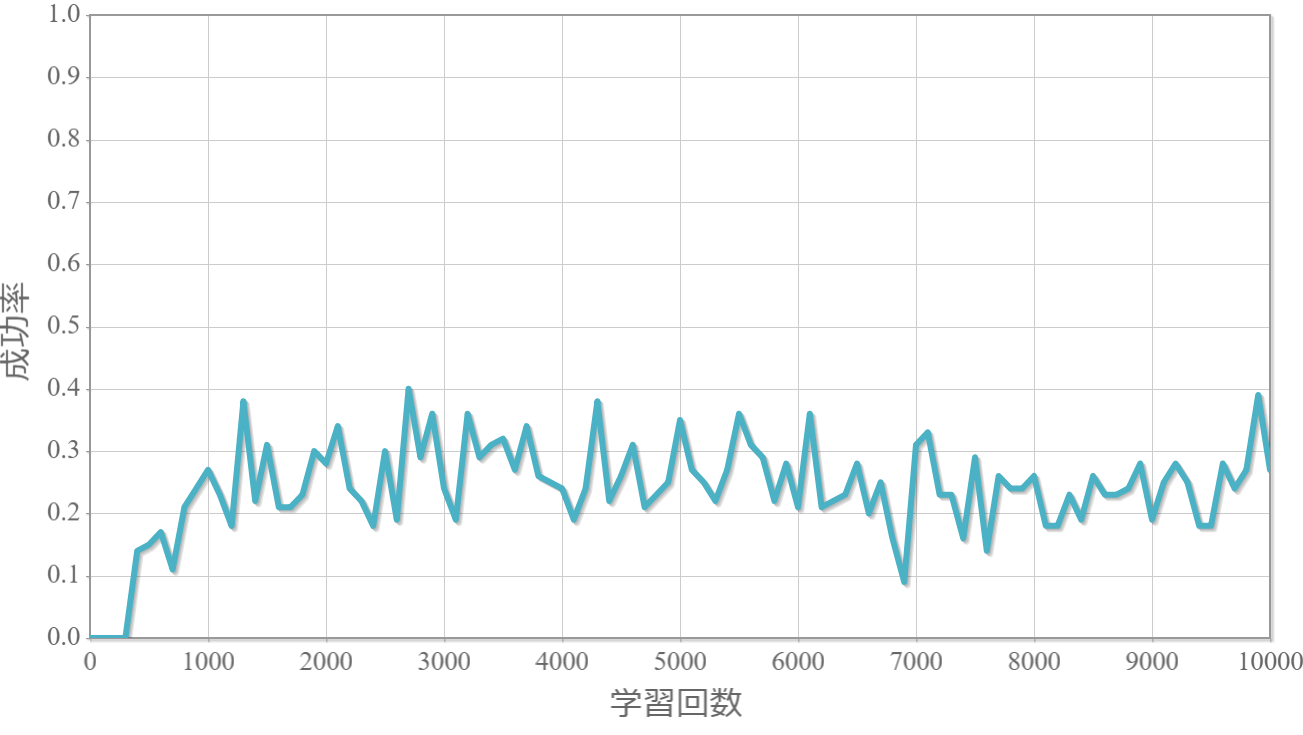
$\gamma=0.9$
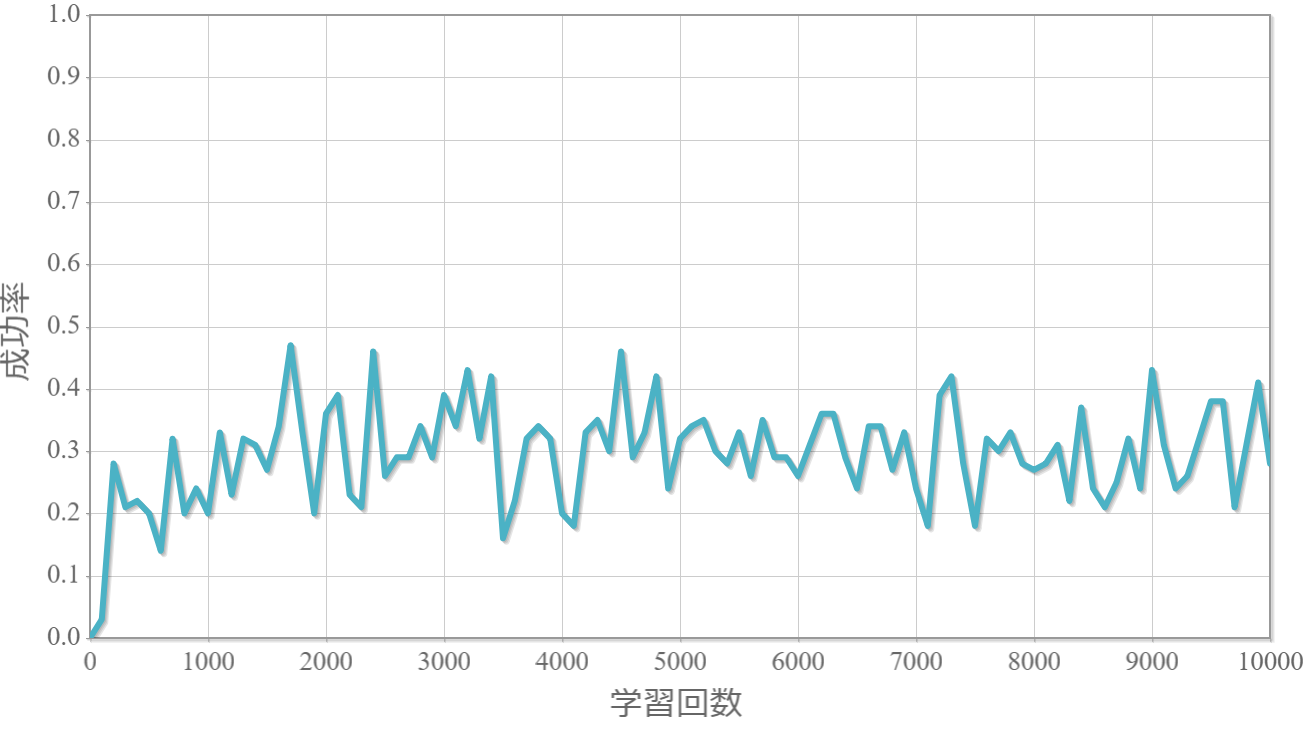
$\gamma=1.0$
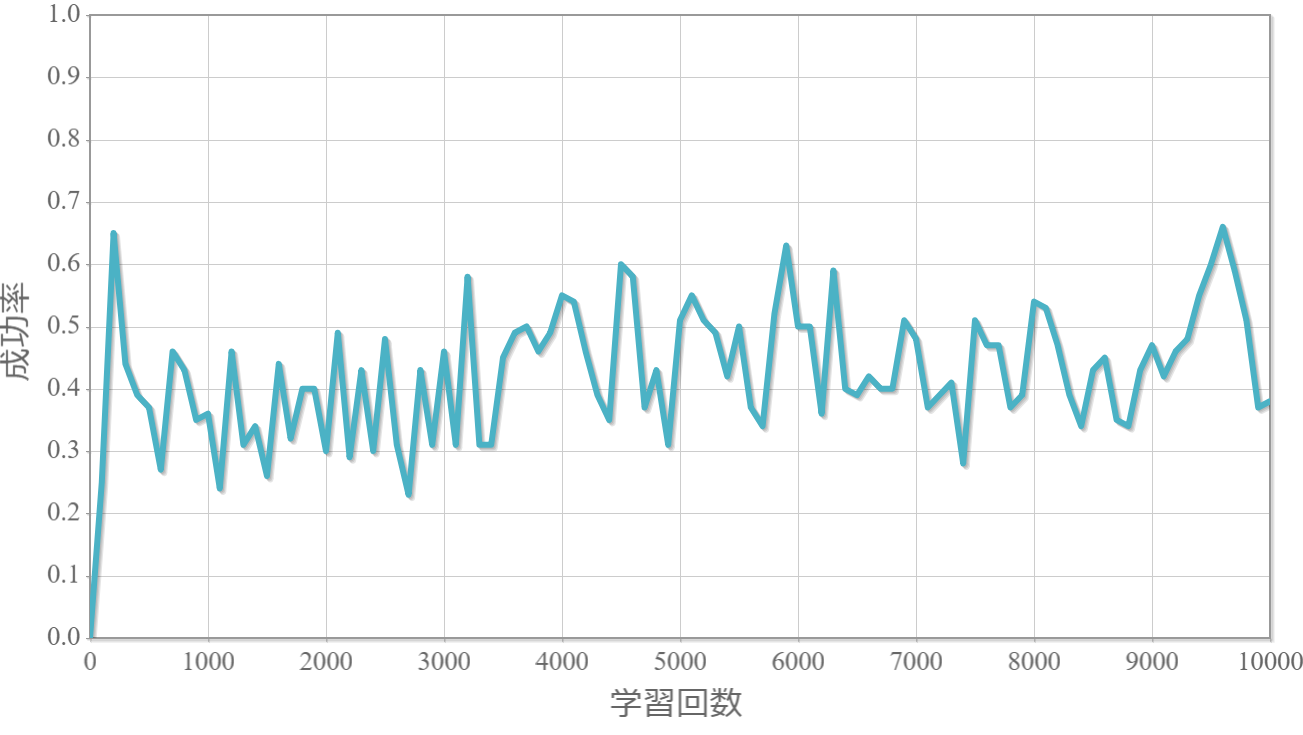
(参考)$\gamma=1.0$でおもりの重さが1/10
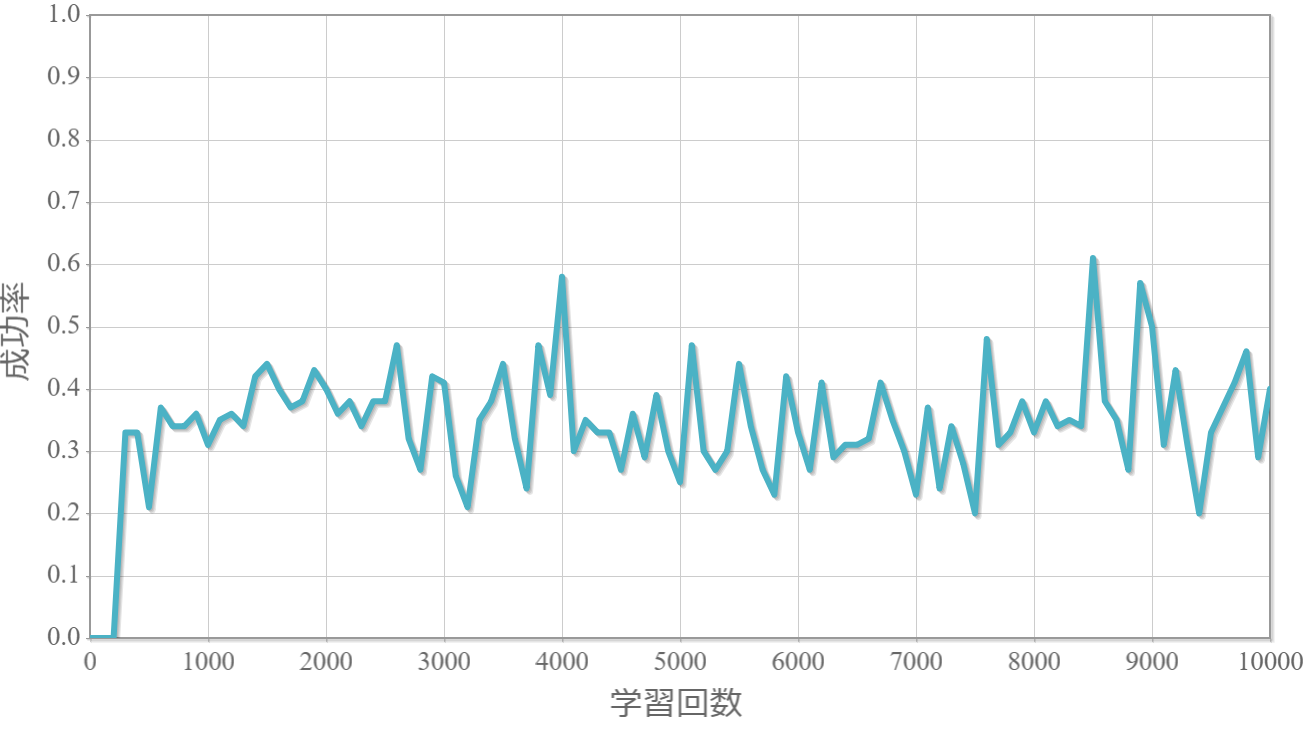
(参考)$\gamma=1.0$, $\epsilon=0.5$(貪欲率)
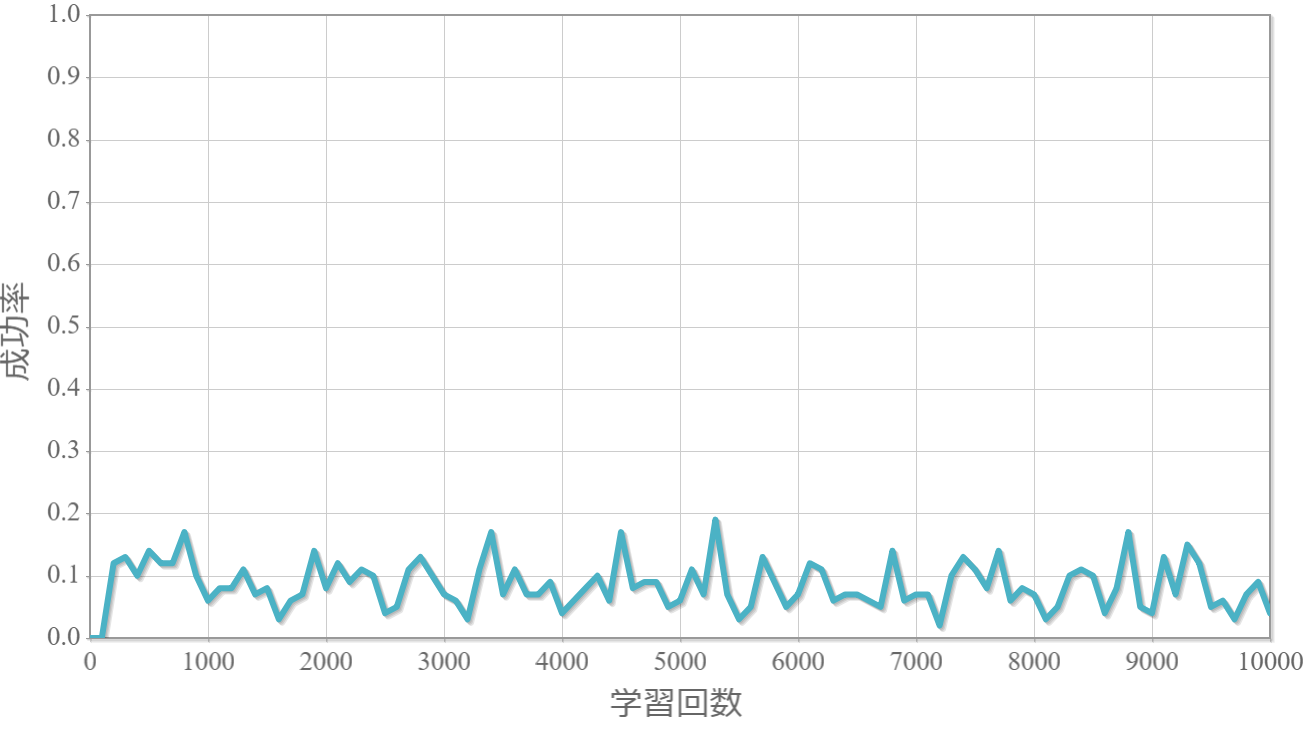
(参考)$\gamma=0.5$, $\epsilon=0.5$(貪欲率)
結果と考察とメモ
・割引率$\gamma$は大きいほうが良い($\gamma=1.0$が最良だった)。
→ これまでの経験から未来に得られる報酬をどの程度考慮するか表す割引率は、外部からのランダムな力が無い単振子運動のような決定論的な現象を対象とする場合には、期待値を割り引く必要がないことを意味していると考えられる。
・滑車の重さが10倍とすることで難易度が下がって達成確率がおよそ+10%となる。
【メモ】学習率を変える
【メモ】環境の場合の数を変える。
【メモ】貪欲率を学習状況によって変化させる
【メモ】ランダムな外力が存在する系。
プログラムソース(C++)
・http://www.natural-science.or.jp/files/NN/20180607-1.zip
※VisualStudio2017のソルーションファイルです。GCC(MinGW)でも動作確認しています。
参考(物理シミュレーション)
 上記シミュレーションは、ルンゲ・クッタ法という常微分方程式を解くアルゴリズムを用いてニュートンの運動方程式を数値的に解いています。本稿で紹介した物理シミュレーションの方法を詳しく解説している書籍です。もしよろしければ「ルンゲ・クッタで行こう!~物理シミュレーションを基礎から学ぶ~(目次)」を参照ください。
上記シミュレーションは、ルンゲ・クッタ法という常微分方程式を解くアルゴリズムを用いてニュートンの運動方程式を数値的に解いています。本稿で紹介した物理シミュレーションの方法を詳しく解説している書籍です。もしよろしければ「ルンゲ・クッタで行こう!~物理シミュレーションを基礎から学ぶ~(目次)」を参照ください。